Artificial Intelligence: Ethics and Regulation
A new policy paper by the UK Government has set out key aims for the regulation of AI. One principle stood out for me, “accountability for the outcomes produced by AI and legal liability must always rest with an identified or identifiable legal person - whether corporate or natural”.
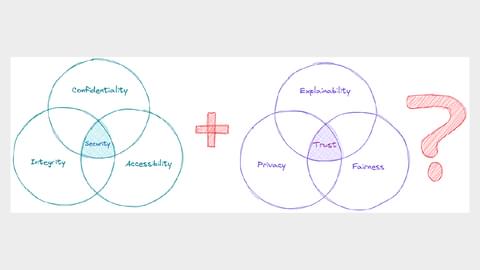
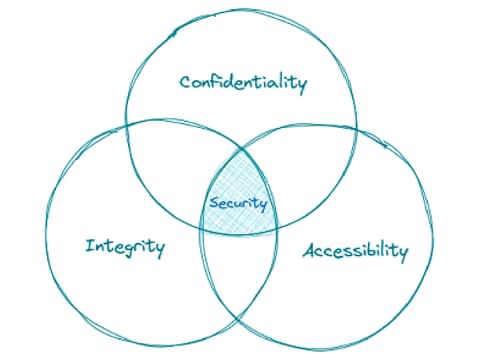
This is a bit like how a Data Protection Officer is tasked with monitoring compliance with the UK GDPR and other data protection laws and policies. Which made me think, as a future “AI Officer”, is there something akin to the CIA triad of confidentiality, integrity and availability that is at the heart of information security?
I checked out a few AI policies/principles at Google, Microsoft and IBM. While they all make valid points, they are all different.
So, I propose the following: Explainability, Privacy and Fairness
Explainability
What would it take for you to trust an AI system with your life, your financial decisions, etc? Trust is not a measurable quality like accuracy or fairness. Instead, it is a characteristic of the human-machine relationship. Explainability and transparency can answer questions like:
- Why did you do that?
- Why not something else?
- How do I correct an error?
And it has already had an impact in areas with existing accountability:
- Autonomous vehicles – highly publicised road traffic incidents involving self-driving cars, has placed an emphasis on increased situational awareness in accidents or other unexpected situations, to both explain and prevent crashes.
- Healthcare – explaining a diagnosis, helps doctors explain how a treatment plan is going to help.
- Loan approvals – Here it creates greater trust whilst mitigating issues related to unfair bias and discrimination.
On a side note, I often get asked, “How can you not know what a computer is doing?”.
Below is an image of a neural network:
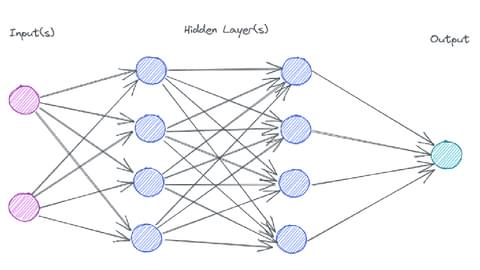
Let’s assume that the inputs on the left are:
- Age
- BMI score
- Number of years spent smoking
- Career category
And the output on the right:
- Percentage chance that a given person will live beyond 80 years old
An explainable model would understand that the nodes in the middle that contribute to the final decision are (making up numbers):
- The career category is about 40% important
- Smoking 35%
- Age 15%
- BMI 10%
Whereas a “Black-Box” AI, even with a list of inputs, no human can understand how the complicated combination of steps are combined/related to each other to reach an outcome.
Privacy
Artificial Intelligence can easily infer sensitive information from insensitive data. For example, based on a person's typing pattern on the keyboard, AI can predict his emotional states such as anxiety, nervousness, and confidence, etc.
This means that while you can apply infosec best practices such as data masking or obfuscation to restrict access to personally identifiable information (PII), you also need to pay attention to the implications of your AI output.
For example, an online retailer developed an AI algorithm to predict buying patterns and send discount coupons to customers' homes. This predictive action made the headlines because it started sending pregnancy-related coupons, resulting in an embarrassing situation for their customers in front of their, uniformed, loved ones.
Fairness
In many ways, bias and fairness in AI are two sides of the same coin. Bias can be introduced at any stage in the AI development pipeline.
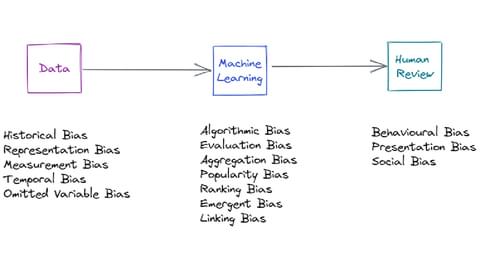
Some of the most infamous issues are to do with data bias, such as training on news articles perpetuating gender-based stereotypes in society (historical bias), or the fact that the data used to train Amazons’ facial recognition was mostly based on white faces, leading to issues with darker-skinned faces (representation bias).
Even if we have perfect data, our learning methods can introduce bias. Benchmarks used to measure the quality of Artificial Intelligence may not represent the general population (evaluation bias) or may simply be overridden by a human reviewer based on their own systemic bias.
We can broadly define fairness as the absence of prejudice or preference for an individual or group based on their characteristics. However, we also need to mindful of tension between group and individual fairness.
For example, while the binary classification model on the left, looks accurate, imagine the data actually contained two different underlying groups, green and orange. These groups could represent different ethnicities, genders, geographical or temporal differences e.g., inside/outside business hours.
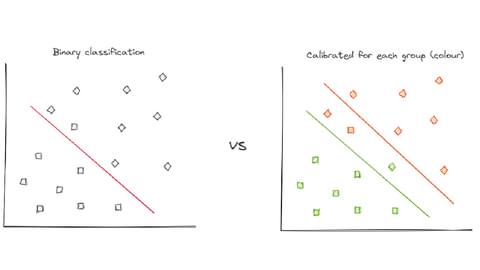
Creating separate group decision boundaries for each group is fairer for the group than a single threshold. However, you need to be mindful of individual fairness for those three individuals who share similar characteristics and fall between the two groups.
Conclusion
What do you think? Are Trust, Privacy and Fairness enough? Have I picked the best ones to focus on?
If you are interested in working with AI and Automation or machine learning, or have an interesting problem to solve, please do get in touch.